The Party is Over: How I Wrote 90,000 Lines of Code for Pennies Before GitHub Killed the PRU System

If you’ve been aggressively leaning on GitHub Copilot’s Agent Mode to do your heavy lifting over the past year, I have some bad news. The absolute joyride we’ve been enjoying at Microsoft’s expense is coming to a grinding halt. On June 1, 2026, GitHub is officially burying its Premium Request Units (PRU) model. In its place comes a strict, metered Usage-Based Billing system powered by "GitHub AI Credits."
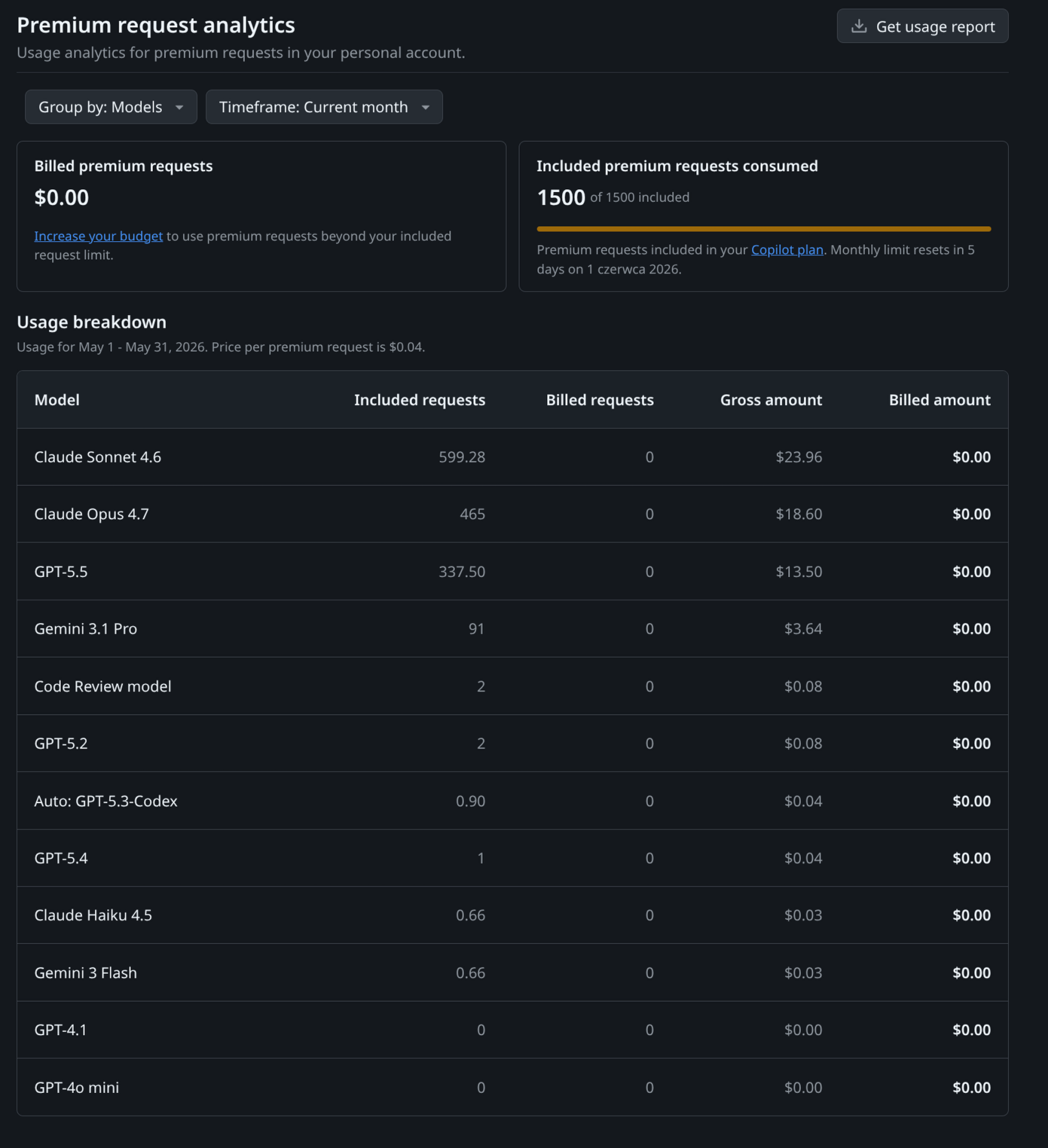
Looking back at May 2026—the absolute final month of the PRU system—it feels like we pulled off a legal heist. I spent those last 28 days putting Copilot’s agentic features through hell across two massive enterprise projects, determined to wring out every drop of value before the window closed.
The final tally? Nearly 90,000 lines of production-ready code shipped while burning just 1,500 Premium Requests.
If I had run those exact same multi-step agent loops, massive codebase context injections, and deep refactoring pipelines directly through raw OpenAI or Anthropic APIs, the invoice would have easily cleared four figures. Instead, it was entirely absorbed by a flat-rate monthly subscription.
Here is the post-mortem of how we gamed the system in its final hours, what those same tokens will cost you under the new June 2026 metered pricing, and the tactical adjustments you need to make to keep your engineering budget from evaporating.
How We Gamed the PRU Era (And Why It’s Dying)
The beauty of the old PRU system lay in its massive blind spot: it counted interactions, completely ignoring the weight of the tokens. It didn't matter if you prompted Copilot with a simple three-line function or if you stuffed ten heavy system files into the context window to force a massive architecture rewrite. To the billing engine, that was exactly 1 Premium Request (or a flat 3x multiplier for heavy flagship models). GitHub absorbed the massive backend inference costs while we freely treated the AI like an entry-level dev working on an infinite data plan. Even better was how Agent Mode operated. You could kick off an autonomous execution loop where the agent analyzed code, executed CLI tools, caught compilation errors, and iterated. Because the billing was tied to the user's initial prompt thread, these massive, multi-turn cognitive loops were heavily subsidized. Obviously, this wasn't sustainable for Microsoft. AI infrastructure costs are tied directly to compute time and token volume. When a fraction of power users start consuming megabytes of context per minute on a $39 plan, the math breaks down.
The New Reality: GitHub AI Credits
Starting June 1, your flat subscription rate stays the same, but it transforms into a fixed pool of GitHub AI Credits (where 1 credit equals $0.01 USD).
Copilot Pro ($10/mo) gives you $10 in monthly credits.
Copilot Pro+ ($39/mo) gives you $39 in monthly credits. Every time your agent reads a file, recalls conversation state, or outputs code, it chips away at that cash balance in real time. The system will track input tokens, output tokens, and—thankfully—cached tokens, charging you the exact market rate of whatever model you've selected. The differences between the two systems highlight just how drastic this shift is:
Feature
The Old PRU System
The New Token System (Post-June 1)
Billing Unit
Flat requests (PRUs)
Raw tokens (Input, Output, Cache)
Context Window
Essentially free to maximize
Highly sensitive; larger files drain credits fast
Agent Behavior
Heavily subsidized per session
Every internal step and tool call bills your pool
Hitting the Ceiling
Fallback to slower, unlimited models
Hard stop (unless you opt into paid overages)
Autocomplete
Unlimited
Remains completely unlimited
Note: For anyone holding onto an annual plan, you will stay on the PRU system until expiration, but GitHub is hiking the model multipliers on June 1 to force a soft alignment with the new reality.
The 2026 Model Tax
The specific model you choose now dictates how long your budget survives. Looking at the latest rate sheets, the price gap between lightweight helpers and heavyweight frontier models is massive. If you insist on letting your agent default to the absolute top-tier intelligence, it is going to cost you. Frontier models like GPT-5.5 or Claude Opus 4.7 sit at the top of the pricing tier, commanding up to $5.00 per million input tokens and a staggering $25.00 to $30.00 per million output tokens. Running a deeply nested agent loop on these models will chew through a $39 Pro+ allotment in a matter of days. On the flip side, lightweight options like GPT-5.4 nano ($0.20 input / $1.25 output per million) or Claude Haiku 4.5 offer a massive discount. Google's Gemini 3 Flash sits comfortably in the middle ($0.50 input / $3.00 output), making it a solid sweet spot for general workflows.
Surviving the Metered Era
Agents are naturally token-hungry. They constantly re-read files to verify state across execution steps. To keep from getting hit with a hard stop in the middle of a sprint, we have to change how we code:
Strict Context Hygiene: Stop letting agents blindly index your entire repository. Be deliberate. Use precise file targeting and clean up your context regularly so you aren't paying for the model to re-read unchanged boilerplate.
Ruthless Model Tiering: Stop using flagship models for everyday tasks. Force your agent to use lightweight models like Haiku or GPT nano for writing unit tests, basic documentation, and boilerplate. Reserve the heavy hitters exclusively for deep architectural refactoring or when the agent gets stuck.
Enforce Spending Caps: If you manage a team or use a corporate seat, go into your billing settings immediately and set a firm spending limit. An autonomous agent trapped in an infinite debugging loop can easily rack up a surprise bill overnight if left unmonitored. The era of free-flowing, careless agent sessions was an incredible run while it lasted. Shipping 90,000 lines of code on 1,500 requests will probably stand as the peak efficiency milestone of early AI development. Moving forward, the tools are just as capable—we just have to become as disciplined with our token budgets as we are with our clean code.